Buffer Overflowとは何か?学習の総まとめ:壊れる流れを言語化してみよう(最終回/全10回)
Buffer Overflow というテーマを、できるだけやさしく、順番に積み上げながら学んできました。
バッファとは何かから始まり、
・配列とメモリの関係
・境界チェック不足
・スタックとローカル変数
・saved RBP と return address
・Segmentation Fault
・オフセット
・64bit環境での見方
・ret2win
までを見てきました。
ここまで学ぶと、1つひとつの言葉はわかってきても、
「全体として何が起きているのか」を、自分の言葉でうまく説明するのは意外と難しいことがあります。
そこで今回の最終回では、Buffer Overflowが起きる流れ全体を、ひとつの話として整理することを目標にします。
つまり今回は、新しい難しい知識を増やすというより、「バッファがあふれると、どうして危険なのか」、「何が、どの順番で壊れていくのか」を言語化する回です。
この“言葉で説明できる力”は、エクスプロイト開発を学ぶうえでとても大切です。

※イメージです。
目次
Buffer Overflowを一言で言うと何か
まず、ここまで学んだ内容を、一言でまとめてみましょう。
Buffer Overflow とは、「用意されたバッファより大きなデータを書き込んでしまい、その範囲をはみ出して周囲のメモリまで壊してしまう現象」です。
![]()
白猫先生
この説明の中で大切なのは、単なる「入れすぎ」では終わらないことです。
白猫先生
もっとやさしく言えば、「小さい箱に大きすぎるデータを入れて、あふれたぶんがとなりまでこわしてしまうこと」です。
本当に危険なのは、あふれたデータが「別の大事な情報まで上書きしてしまう」ところにあります。
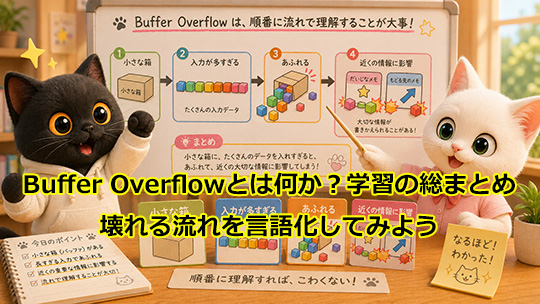
つまり Buffer Overflow は、
・小さい箱がある。
・そこへ大きすぎる情報を入れる。
・箱の外まで書いてしまう。
・その先にある大事なものが壊れる。
という流れで理解すると、とてもわかりやすくなります。
![]()
白猫先生
白猫先生
簡単にたとえるなら、「自分のノートの欄に書くはずが、はみ出して先生の大事なメモまで汚してしまう」ことです。
壊れる流れを順番に整理してみよう
ここで、Buffer Overflow がどのように進んでいくのかを順番に整理してみます。
1.バッファが用意される。
たとえば関数の中に、
char buf[16];
のようなローカル変数があるとします。
これは16バイトぶんの小さな箱です。
2.入力がコピーされる。
そこへ"strcpy()"のような、長さ確認をしないコピーが行われると、入力が長すぎた場合に"buf"に収まりきらなくなります。
3.バッファの外へ書き込みが進む。
本来は"buf"の中だけに入るはずのデータが、その先の領域まで進んでしまいます。
これが「オーバーフロー」です。
4.近くの大事な情報に影響する。
スタック上では、ローカル変数の近くに「saved RB」、「return address」などの大切な情報があることがあります。
そのため、バッファのあふれがそこまで届くと、関数の動きそのものに影響する可能性があります。
5.クラッシュや流れの変化が起きる。
return addressが壊れると、本来戻る場所ではない変な場所へ飛ぼうとすることがあります。
その結果、Segmentation Faultが起きたり、場合によっては別の関数へ流れが変わったりします。
このように、Buffer Overflow は「長い入力で落ちた」だけの話ではなく、「入力がどこまで届き、何を壊したか」を順番に考える問題なのです。
なぜreturn addressがそんなに重要なのか
シリーズの中でも、特に大事な言葉が「return address」でした。
return addressは、関数の処理が終わったあとに「どこへ戻るか」を表す情報です。
たとえば"main()"から"vuln()"を呼んだとき、"vuln()"が終わったあとには"main()"の続きへ戻る必要があります。
その戻る先を覚えているのがreturn addressです。
つまり、return addressは「プログラムの道案内」のようなものです。
もしこの道案内が正しいなら、プログラムは元の流れへ戻れます。
ですが、もしこの情報が壊れてしまったらどうなるでしょうか。
本来の道ではなく、別の道へ進んでしまうかもしれません。
その結果、
・変な場所へ飛ぶ。
・実行できない場所へ飛んでクラッシュする。
・学習用の"win()"関数へ飛ぶ。
といったことが起こりえます。
だからBuffer Overflowの学習では、単に「バッファがあふれる」だけでなく、その先にあるreturn addressに届くかどうかがとても重要になるのです。
サンプルコードで全体を振り返る
ここで、第1部の総まとめとしてシンプルなコードを見てみます。
-----
#include <stdio.h>
#include <string.h>
void win(void) {
printf("Reached win!\n");
}
void vuln(char *input) {
char buf[16];
strcpy(buf, input);
printf("Input: %s\n", buf);
}
int main(int argc, char *argv[]) {
if (argc > 1) {
vuln(argv[1]);
}
return 0;
}
-----
このコードには、第1部で学んだ大事な要素がほぼ全部入っています。
まず、
char buf[16];
はローカルバッファです。
関数 "vuln()" の中で作られるので、スタック上に置かれることが多いです。
次に、
strcpy(buf, input);
は、入力をそのままコピーしています。
ここで長さ確認がないため、"input"が長すぎるとBuffer Overflowの原因になります。
さらに、"vuln()"の近くにはreturn addressなどの大事な情報があります。
そのため、"buf"の外へ書き込みが進むと、プログラムの流れに影響する可能性があります。
そして、
void win(void) {
printf("Reached win!\n");
}
という"win()"は、ret2winの学習で出てきた特別な関数です。
もし本来の戻り先ではなくここへ流れが変われば、制御奪取の基本が見えやすくなります。
このコードから言えることは、Buffer Overflowは単なる文字列処理のミスではなく、入力、メモリ、スタック、戻り先、制御の変化が全部つながった現象だということです。
「理解したつもり」で終わらないために大切なこと
ここまで学んできた内容を、本当に自分の力にするために大切なのは、自分の言葉で説明できることです。
たとえば次のような問いに、自分で答えられるかを試してみるとよいです。
・バッファとは何か。
・なぜ長い入力で危険になるのか。
・境界チェック不足とは何か。
・スタック上のローカル変数がなぜ危険なのか。
・return addressは何をしているのか。
・Segmentation Faultは何を教えてくれるのか。
・オフセットとは何か。
・ret2winは何を学ぶための考え方なのか。
これらを丸暗記ではなく、自分の言葉でやさしく説明できるようになると、理解はかなり深まっています。
![]()
白猫先生
エクスプロイト開発は、難しい単語を知っていることよりも、壊れる流れを順番に説明できることがとても重要です。
白猫先生
簡単にたとえるなら、「テストで答えを覚えるだけではなく、友だちに説明できる状態」を目指すことが大切です。
Buffer Overflowとは何か?学習の総まとめ:壊れる流れを言語化してみようのまとめ
今回学んだ大事なことは、Buffer Overflow を単なる「長い入力で落ちる現象」としてではなく、バッファ、メモリ、スタック、return address、クラッシュ、制御奪取までを含めた一連の流れとして理解することです。
関数の中にある小さなバッファへ、長さ確認なしで大きすぎる入力を書き込むと、その範囲をこえて周囲のメモリまで壊してしまう可能性があります。特にスタック上では、ローカル変数の近くにsaved RBPやreturn addressがあるため、あふれたデータがそこまで届くと、プログラムの戻り先や進み方そのものに影響することがあります。
その結果として、Segmentation Faultが起きたり、ret2winのように別の関数へ流れが変わることもあります。つまり、Buffer Overflowの本質は、どこまで入力が届き、何を壊し、どう流れが変わるのかを順番に考えることにあります。
これで、「Buffer Overflow 超基礎シリーズ」全10回が、終了しました。
ありかとうございました。
